The Delta transaction log for the ‘students’ tables is shown using the ‘DESCRIBE HISTORY students’ command. A Data Engineer needs to query the table as it existed before the UPDATE operation listed in the log.
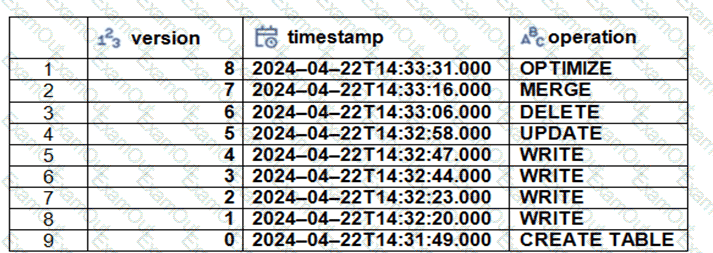
Which command should the Data Engineer use to achieve this? (Choose two.)
A data engineer is designing an ETL pipeline to process both streaming and batch data from multiple sources The pipeline must ensure data quality, handle schema evolution, and provide easy maintenance. The team is considering using Delta Live Tables (DLT) in Databricks to achieve these goals. They want to understand the key features and benefits of DLT that make it suitable for this use case.
Why is Delta Live Tables (DLT) an appropriate choice?
Identify how the count_if function and the count where x is null can be used
Consider a table random_values with below data.
What would be the output of below query?
select count_if(col > 1) as count_a. count(*) as count_b.count(col1) as count_c from random_values col1
0
1
2
NULL -
2
3
A data analyst has a series of queries in a SQL program. The data analyst wants this program to run every day. They only want the final query in the program to run on Sundays. They ask for help from the data engineering team to complete this task.
Which of the following approaches could be used by the data engineering team to complete this task?
Which of the following is a benefit of the Databricks Lakehouse Platform embracing open source technologies?
A data engineer is using the following code block as part of a batch ingestion pipeline to read from a composable table:

Which of the following changes needs to be made so this code block will work when the transactions table is a stream source?
A data engineering team has two tables. The first table march_transactions is a collection of all retail transactions in the month of March. The second table april_transactions is a collection of all retail transactions in the month of April. There are no duplicate records between the tables.
Which of the following commands should be run to create a new table all_transactions that contains all records from march_transactions and april_transactions without duplicate records?
What Databricks feature can be used to check the data sources and tables used in a workspace?
Which of the following data workloads will utilize a Gold table as its source?
Which file format is used for storing Delta Lake Table?
