A company is collaborating with a partner that does not use Databricks but needs access to a large historical dataset stored in Delta format. The data engineer needs to ensure that the partner can access the data securely, without the need for them to set up an account, and with read-only access.
How should the data be shared?
In order for Structured Streaming to reliably track the exact progress of the processing so that it can handle any kind of failure by restarting and/or reprocessing, which of the following two approaches is used by Spark to record the offset range of the data being processed in each trigger?
What is the functionality of AutoLoader in Databricks?
A data engineer is onboarding a new Bronze ingestion pipeline in Databricks with Unity Catalog. The team wants Databricks to handle storage layout, apply platform optimizations over time, and simplify lifecycle management so that when a table is dropped, its underlying data is also cleaned up according to Databricks-managed retention policies.
Which table type should the data engineer create for these ingestion tables?
Which of the following must be specified when creating a new Delta Live Tables pipeline?
A data engineer needs to conduct Exploratory Data Analysis (EDA) on data residing in a database within the company’s custom-defined cloud network . The data engineer is using SQL for this task.
Which type of SQL Warehouse will enable the data engineer to process large numbers of queries quickly and cost-effectively?
A data analyst has created a Delta table sales that is used by the entire data analysis team. They want help from the data engineering team to implement a series of tests to ensure the data is clean. However, the data engineering team uses Python for its tests rather than SQL.
Which of the following commands could the data engineering team use to access sales in PySpark?
A data engineer is processing ingested streaming tables and needs to filter out NULL values in the order_datetime column from the raw streaming table orders_raw and store the results in a new table orders_valid using DLT.
Which code snippet should the data engineer use?
A)
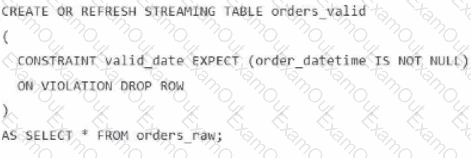
B)
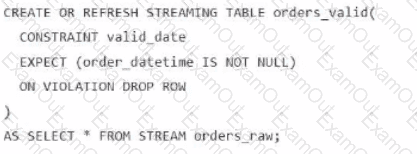
C)
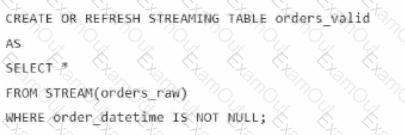
D)

What is stored in a Databricks customer ' s cloud account?
Which of the following SQL keywords can be used to convert a table from a long format to a wide format?
