Spill occurs as a result of executing various wide transformations. However, diagnosing spill requires one to proactively look for key indicators.
Where in the Spark UI are two of the primary indicators that a partition is spilling to disk?
A production workload incrementally applies updates from an external Change Data Capture feed to a Delta Lake table as an always-on Structured Stream job. When data was initially migrated for this table, OPTIMIZE was executed and most data files were resized to 1 GB. Auto Optimize and Auto Compaction were both turned on for the streaming production job. Recent review of data files shows that most data files are under 64 MB, although each partition in the table contains at least 1 GB of data and the total table size is over 10 TB.
Which of the following likely explains these smaller file sizes?
A table is registered with the following code:
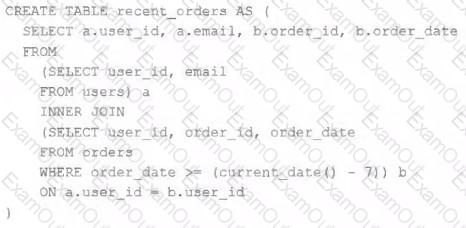
Both users and orders are Delta Lake tables. Which statement describes the results of querying recent_orders ?
The business reporting tem requires that data for their dashboards be updated every hour. The total processing time for the pipeline that extracts transforms and load the data for their pipeline runs in 10 minutes.
Assuming normal operating conditions, which configuration will meet their service-level agreement requirements with the lowest cost?
A table named user_ltv is being used to create a view that will be used by data analysts on various teams. Users in the workspace are configured into groups, which are used for setting up data access using ACLs.
The user_ltv table has the following schema:
email STRING, age INT, ltv INT
The following view definition is executed:
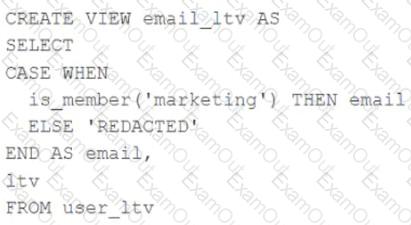
An analyst who is not a member of the marketing group executes the following query:
SELECT * FROM email_ltv
Which statement describes the results returned by this query?
A Data Engineer is building a simple data pipeline using Lakeflow Declarative Pipelines (LDP) in Databricks to ingest customer data. The raw customer data is stored in a cloud storage location in JSON format. The task is to create Lakeflow Declarative Pipelines that read the raw JSON data and write it into a Delta table for further processing.
Which code snippet will correctly ingest the raw JSON data and create a Delta table using LDP?
A data engineer is using Lakeflow Declarative Pipelines Expectations feature to track the data quality of their incoming sensor data. Periodically, sensors send bad readings that are out of range, and they are currently flagging those rows with a warning and writing them to the silver table along with the good data. They’ve been given a new requirement – the bad rows need to be quarantined in a separate quarantine table and no longer included in the silver table.
This is the existing code for their silver table:
@dlt.table
@dlt.expect( " valid_sensor_reading " , " reading < 120 " )
def silver_sensor_readings():
return spark.readStream.table( " bronze_sensor_readings " )
What code will satisfy the requirements?
A data engineer is creating a data ingestion pipeline to understand where customers are taking their rented bicycles during use. The engineer noticed that, over time, data being transmitted from the bicycle sensors fail to include key details like latitude and longitude. Downstream analysts need both the clean records and the quarantined records available for separate processing.
The data engineer already has this code:
import dlt
from pyspark.sql.functions import expr
rules = {
" valid_lat " : " (lat IS NOT NULL) " ,
" valid_long " : " (long IS NOT NULL) "
}
quarantine_rules = " NOT({}) " .format( " AND " .join(rules.values()))
@dlt.view
def raw_trips_data():
return spark.readStream.table( " ride_and_go.telemetry.trips " )
How should the data engineer meet the requirements to capture good and bad data?
Which statement describes the correct use of pyspark.sql.functions.broadcast?
A Delta Lake table in the Lakehouse named customer_parsams is used in churn prediction by the machine learning team. The table contains information about customers derived from a number of upstream sources. Currently, the data engineering team populates this table nightly by overwriting the table with the current valid values derived from upstream data sources.
Immediately after each update succeeds, the data engineer team would like to determine the difference between the new version and the previous of the table.
Given the current implementation, which method can be used?
