A DataFrame df has columns name, age, and salary. The developer needs to sort the DataFrame by age in ascending order and salary in descending order.
Which code snippet meets the requirement of the developer?
The following code fragment results in an error:
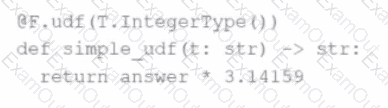
Which code fragment should be used instead?
A)

B)

C)

D)

14 of 55.
A developer created a DataFrame with columns color, fruit, and taste, and wrote the data to a Parquet directory using:
df.write.partitionBy("color", "taste").parquet("/path/to/output")
What is the result of this code?
18 of 55.
An engineer has two DataFrames — df1 (small) and df2 (large). To optimize the join, the engineer uses a broadcast join:
from pyspark.sql.functions import broadcast
df_result = df2.join(broadcast(df1), on="id", how="inner")
What is the purpose of using broadcast() in this scenario?
Given a CSV file with the content:

And the following code:
from pyspark.sql.types import *
schema = StructType([
StructField("name", StringType()),
StructField("age", IntegerType())
])
spark.read.schema(schema).csv(path).collect()
What is the resulting output?
What is the relationship between jobs, stages, and tasks during execution in Apache Spark?
Options:
Given the schema:

event_ts TIMESTAMP,
sensor_id STRING,
metric_value LONG,
ingest_ts TIMESTAMP,
source_file_path STRING
The goal is to deduplicate based on: event_ts, sensor_id, and metric_value.
Options:
1 of 55. A data scientist wants to ingest a directory full of plain text files so that each record in the output DataFrame contains the entire contents of a single file and the full path of the file the text was read from.
The first attempt does read the text files, but each record contains a single line. This code is shown below:
txt_path = "/datasets/raw_txt/*"
df = spark.read.text(txt_path) # one row per line by default
df = df.withColumn("file_path", input_file_name()) # add full path
Which code change can be implemented in a DataFrame that meets the data scientist's requirements?
Given:
python
CopyEdit
spark.sparkContext.setLogLevel("
Which set contains the suitable configuration settings for Spark driver LOG_LEVELs?
A Data Analyst needs to retrieve employees with 5 or more years of tenure.
Which code snippet filters and shows the list?
