An existing integration is implemented in Appian. Its role is to send data for the main case and its related objects in a complex JSON to a REST API, to insert new information into an existing application. This integration was working well for a while. However, the customer highlighted one specific scenario where the integration failed in Production, and the API responded with a 500 Internal Error code. The project is in Post-Production Maintenance, and the customer needs your assistance. Which three steps should you take to troubleshoot the issue?
Send the same payload to the test API to ensure the issue is not related to the API environment.
Send a test case to the Production API to ensure the service is still up and running.
Analyze the behavior of subsequent calls to the Production API to ensure there is no global issue, and ask the customer to analyze the API logs to understand the nature of the issue.
Obtain the JSON sent to the API and validate that there is no difference between the expected JSON format and the sent one.
Ensure there were no network issues when the integration was sent.
The Answer Is:
A, C, DExplanation:
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer in a Post-Production Maintenance phase, troubleshooting a failed integration (HTTP 500 Internal Server Error) requires a systematic approach to isolate the root cause—whether it’s Appian-side, API-side, or environmental. A 500 error typically indicates an issue on the server (API) side, but the developer must confirm Appian’s contribution and collaborate with the customer. The goal is to select three steps that efficiently diagnose the specific scenario while adhering to Appian’s best practices. Let’s evaluate each option:
A. Send the same payload to the test API to ensure the issue is not related to the API environment:This is a critical step. Replicating the failure by sending the exact payload (from the failed Production call) to a test API environment helps determine if the issue is environment-specific (e.g., Production-only configuration) or inherent to the payload/API logic. Appian’s Integration troubleshooting guidelines recommend testing in a non-Production environment first to isolate variables. If the test API succeeds, the Production environment or API state is implicated; if it fails, the payload or API logic is suspect. This step leverages Appian’s Integration object logging (e.g., request/response capture) and is a standard diagnostic practice.
B. Send a test case to the Production API to ensure the service is still up and running:While verifying Production API availability is useful, sending an arbitrary test case risks further Production disruption during maintenance and may not replicate the specific scenario. A generic test might succeed (e.g., with simpler data), masking the issue tied to the complex JSON. Appian’s Post-Production guidelines discourage unnecessary Production interactions unless replicating the exact failure is controlled and justified. This step is less precise than analyzing existing behavior (C) and is not among the top three priorities.
C. Analyze the behavior of subsequent calls to the Production API to ensure there is no global issue, and ask the customer to analyze the API logs to understand the nature of the issue:This is essential. Reviewing subsequent Production calls (via Appian’s Integration logs or monitoring tools) checks if the 500 error is isolated or systemic (e.g., API outage). Since Appian can’t access API server logs, collaborating with the customer to review their logs is critical for a 500 error, which often stems from server-side exceptions (e.g., unhandled data). Appian Lead Developer training emphasizes partnership with API owners and using Appian’s Process History or Application Monitoring to correlate failures—making this a key troubleshooting step.
D. Obtain the JSON sent to the API and validate that there is no difference between the expected JSON format and the sent one:This is a foundational step. The complex JSON payload is central to the integration, and a 500 error could result from malformed data (e.g., missing fields, invalid types) that the API can’t process. In Appian, you can retrieve the sent JSON from the Integration object’s execution logs (if enabled) or Process Instance details. Comparing it against the API’s documented schema (e.g., via Postman or API specs) ensures Appian’s output aligns with expectations. Appian’s documentation stresses validating payloads as a first-line check for integration failures, especially in specific scenarios.
E. Ensure there were no network issues when the integration was sent:While network issues (e.g., timeouts, DNS failures) can cause integration errors, a 500 Internal Server Error indicates the request reached the API and triggered a server-side failure—not a network issue (which typically yields 503 or timeout errors). Appian’s Connected System logs can confirm HTTP status codes, and network checks (e.g., via IT teams) are secondary unless connectivity is suspected. This step is less relevant to the 500 error and lower priority than A, C, and D.
Conclusion: The three best steps are A (test API with same payload), C (analyze subsequent calls and customer logs), and D (validate JSON payload). These steps systematically isolate the issue—testing Appian’s output (D), ruling out environment-specific problems (A), and leveraging customer insights into the API failure (C). This aligns with Appian’s Post-Production Maintenance strategies: replicate safely, analyze logs, and validate data.
The business database for a large, complex Appian application is to undergo a migration between database technologies, as well as interface and process changes. The project manager asks you to recommend a test strategy. Given the changes, which two items should be included in the test strategy?
Internationalization testing of the Appian platform
A regression test of all existing system functionality
Penetration testing of the Appian platform
Tests for each of the interfaces and process changes
Tests that ensure users can still successfully log into the platform
The Answer Is:
B, DExplanation:
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, recommending a test strategy for a large, complex application undergoing a database migration (e.g., from Oracle to PostgreSQL) and interface/process changes requires focusing on ensuring system stability, functionality, and the specific updates. The strategy must address risks tied to the scope—database technology shift, interface modifications, and process updates—while aligning with Appian’s testing best practices. Let’s evaluate each option:
A. Internationalization testing of the Appian platform:Internationalization testing verifies that the application supports multiple languages, locales, and formats (e.g., date formats). While valuable for global applications, the scenario doesn’t indicate a change in localization requirements tied to the database migration, interfaces, or processes. Appian’s platform handles internationalization natively (e.g., via locale settings), and this isn’t impacted by database technology or UI/process changes unless explicitly stated. This is out of scope for the given context and not a priority.
B. A regression test of all existing system functionality:This is a critical inclusion. A database migration between technologies can affect data integrity, queries (e.g., a!queryEntity), and performance due to differences in SQL dialects, indexing, or drivers. Regression testing ensures that all existing functionality—records, reports, processes, and integrations—works as expected post-migration. Appian Lead Developer documentation mandates regression testing for significant infrastructure changes like this, as unmapped edge cases (e.g., datatype mismatches) could break the application. Given the “large, complex” nature, full-system validation is essential to catch unintended impacts.
C. Penetration testing of the Appian platform:Penetration testing assesses security vulnerabilities (e.g., injection attacks). While security is important, the changes described—database migration, interface, and process updates—don’t inherently alter Appian’s security model (e.g., authentication, encryption), which is managed at the platform level. Appian’s cloud or on-premise security isn’t directly tied to database technology unless new vulnerabilities are introduced (not indicated here). This is a periodic concern, not specific to this migration, making it less relevant than functional validation.
D. Tests for each of the interfaces and process changes:This is also essential. The project includes explicit “interface and process changes” alongside the migration. Interface updates (e.g., SAIL forms) might rely on new data structures or queries, while process changes (e.g., modified process models) could involve updated nodes or logic. Testing each change ensures these components function correctly with the new database and meet business requirements. Appian’s testing guidelines emphasize targeted validation of modified components to confirm they integrate with the migrated data layer, making this a primary focus of the strategy.
E. Tests that ensure users can still successfully log into the platform:Login testing verifies authentication (e.g., SSO, LDAP), typically managed by Appian’s security layer, not the business database. A database migration affects application data, not user authentication, unless the database stores user credentials (uncommon in Appian, which uses separate identity management). While a quick sanity check, it’s narrow and subsumed by broader regression testing (B), making it redundant as a standalone item.
Conclusion: The two key items are B (regression test of all existing system functionality) and D (tests for each of the interfaces and process changes). Regression testing (B) ensures the database migration doesn’t disrupt the entire application, while targeted testing (D) validates the specific interface and process updates. Together, they cover the full scope—existing stability and new functionality—aligning with Appian’s recommended approach for complex migrations and modifications.
For each scenario outlined, match the best tool to use to meet expectations. Each tool will be used once
Note: To change your responses, you may deselected your response by clicking the blank space at the top of the selection list.

The Answer Is:
Explanation:
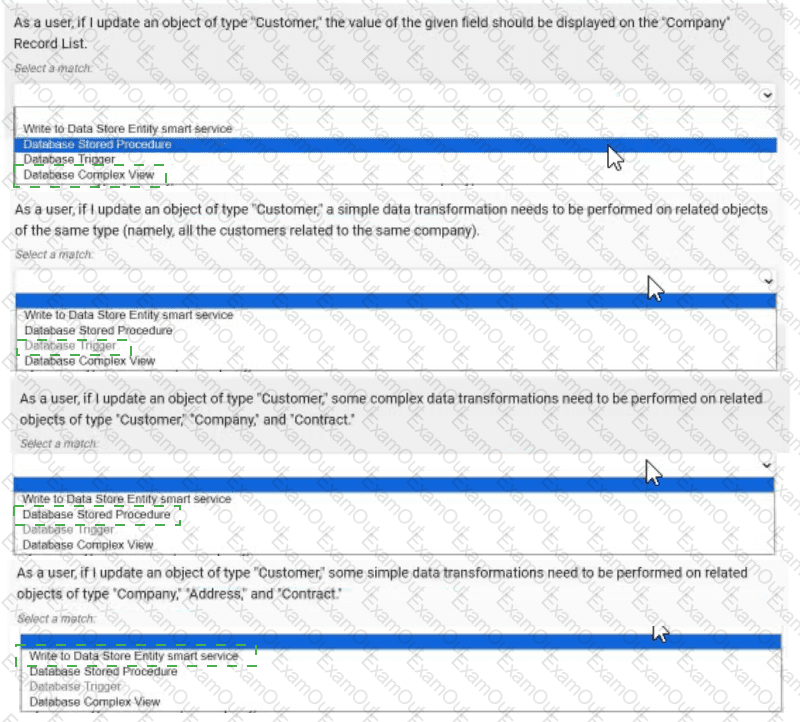
As a user, if I update an object of type "Customer", the value of the given field should be displayed on the "Company" Record List. → Database Complex View
As a user, if I update an object of type "Customer", a simple data transformation needs to be performed on related objects of the same type (namely, all the customers related to the same company). → Database Trigger
As a user, if I update an object of type "Customer", some complex data transformations need to be performed on related objects of type "Customer", "Company", and "Contract". → Database Stored Procedure
As a user, if I update an object of type "Customer", some simple data transformations need to be performed on related objects of type "Company", "Address", and "Contract". → Write to Data Store Entity smart service
Comprehensive and Detailed In-Depth Explanation:
Appian integrates with external databases to handle data updates and transformations, offering various tools depending on the complexity and context of the task. The scenarios involve updating a "Customer" object and triggering actions on related data, requiring careful selection of the best tool. Appian’s Data Integration and Database Management documentation guides these decisions.
As a user, if I update an object of type "Customer", the value of the given field should be displayed on the "Company" Record List → Database Complex View:This scenario requires displaying updated customer data on a "Company" Record List, implying a read-only operation to join or aggregate data across tables. A Database Complex View (e.g., a SQL view combining "Customer" and "Company" tables) is ideal for this. Appian supports complex views to predefine queries that can be used in Record Lists, ensuring the updated field value is reflected without additional processing. This tool is best for read operations and does not involve write logic.
As a user, if I update an object of type "Customer", a simple data transformation needs to be performed on related objects of the same type (namely, all the customers related to the same company) → Database Trigger:This involves a simple transformation (e.g., updating a flag or counter) on related "Customer" records after an update. A Database Trigger, executed automatically on the database side when a "Customer" record is modified, is the best fit. It can perform lightweight SQL updates on related records (e.g., via a company ID join) without Appian process overhead. Appian recommends triggers for simple, database-level automation, especially when transformations are confined to the same table type.
As a user, if I update an object of type "Customer", some complex data transformations need to be performed on related objects of type "Customer", "Company", and "Contract" → Database Stored Procedure:This scenario involves complex transformations across multiple related object types, suggesting multi-step logic (e.g., recalculating totals or updating multiple tables). A Database Stored Procedure allows you to encapsulate this logic in SQL, callable from Appian, offering flexibility for complex operations. Appian supports stored procedures for scenarios requiring transactional integrity and intricate data manipulation across tables, making it the best choice here.
As a user, if I update an object of type "Customer", some simple data transformations need to be performed on related objects of type "Company", "Address", and "Contract" → Write to Data Store Entity smart service:This requires simple transformations on related objects, which can be handled within Appian’s process model. The "Write to Data Store Entity" smart service allows you to update multiple related entities (e.g., "Company", "Address", "Contract") based on the "Customer" update, using Appian’s expression rules for logic. This approach leverages Appian’s process automation, is user-friendly for developers, and is recommended for straightforward updates within the Appian environment.
Matching Rationale:
Each tool is used once, covering the spectrum of database integration options: Database Complex View for read/display, Database Trigger for simple database-side automation, Database Stored Procedure for complex multi-table logic, and Write to Data Store Entity smart service for Appian-managed simple updates.
Appian’s guidelines prioritize using the right tool based on complexity and context, ensuring efficiency and maintainability.
You are selling up a new cloud environment. The customer already has a system of record for Its employees and doesn't want to re-create them in Appian. so you are going to Implement LDAP authentication.
What are the next steps to configure LDAP authentication?
To answer, move the appropriate steps from the Option list to the Answer List area, and arrange them in the correct order. You may or may not use all the steps.

The Answer Is:

Explanation:
Navigate to the Admin console > Authentication > LDAP. This is the first step, as it allows you to access the settings and options for LDAP authentication in Appian.
Work with the customer LDAP point of contact to obtain the LDAP authentication xsd. Import the xsd file in the Admin console. This is the second step, as it allows you to define the schema and structure of the LDAP data that will be used for authentication in Appian. You will need to work with the customer LDAP point of contact to obtain the xsd file that matches their LDAP server configuration and data model. You will then need to import the xsd file in the Admin console using the Import Schema button.
Enable LDAP and enter the LDAP parameters, such as the URL of the LDAP server and plaintext credentials. This is the third step, as it allows you to enable and configure the LDAP authentication in Appian. You will need to check the Enable LDAP checkbox and enter the required parameters, such as the URL of the LDAP server, the plaintext credentials for connecting to the LDAP server, and the base DN for searching for users in the LDAP server.
Test the LDAP integration and see if it succeeds. This is the fourth and final step, as it allows you to verify and validate that the LDAP authentication is working properly in Appian. You will need to use the Test Connection button to test if Appian can connect to the LDAP server successfully. You will also need to use the Test User Lookup button to test if Appian can find and authenticate a user from the LDAP server using their username and password.
Configuring LDAP authentication in Appian Cloud allows the platform to leverage an existing employee system of record (e.g., Active Directory) for user authentication, avoiding manual user creation. The process involves a series of steps within the Appian Administration Console, guided by Appian’s Security and Authentication documentation. The steps must be executed in a logical order to ensure proper setup and validation.
Navigate to the Admin Console > Authentication > LDAP:The first step is to access the LDAP configuration section in the Appian Administration Console. This is the entry point for enabling and configuring LDAP authentication, where administrators can define the integration settings. Appian requires this initial navigation to begin the setup process.
Work with the customer LDAP point-of-contact to obtain the LDAP authentication xsd. Import the xsd file in the Admin Console:The next step involves gathering the LDAP schema definition (xsd file) from the customer’s LDAP system (e.g., via their point-of-contact). This file defines the structure of the LDAP directory (e.g., user attributes). Importing it into the Admin Console allows Appian to map these attributes to its user model, a critical step before enabling authentication, as outlined in Appian’s LDAP Integration Guide.
Enable LDAP and enter the appropriate LDAP parameters, such as the URL of the LDAP server and plaintext credentials:After importing the schema, enable LDAP and configure the connection details. This includes specifying the LDAP server URL (e.g., ldap://ldap.example.com) and plaintext credentials (or a secure alternative like LDAPS with certificates). These parameters establish the connection to the customer’s LDAP system, a prerequisite for testing, as per Appian’s security best practices.
Test the LDAP integration and save if it succeeds:The final step is to test the configuration to ensure Appian can authenticate against the LDAP server. The Admin Console provides a test option to verify connectivity and user synchronization. If successful, saving the configuration applies the settings, completing the setup. Appian recommends this validation step to avoid misconfigurations, aligning with the iterative testing approach in the documentation.
Unused Option:
Enter two parameters: the URL of the LDAP server and plaintext credentials:This step is redundant and not used. The equivalent action is covered under "Enable LDAP and enter the appropriate LDAP parameters," which is more comprehensive and includes enabling the feature. Including both would be duplicative, and Appian’s interface consolidates parameter entry with enabling.
Ordering Rationale:
The sequence follows a logical workflow: navigation to the configuration area, schema import for structure, parameter setup for connectivity, and testing/saving for validation. This aligns with Appian’s step-by-step LDAP setup process, ensuring each step builds on the previous one without requiring backtracking.
The unused option reflects the question’s allowance for not using all steps, indicating flexibility in the process.
For each requirement, match the most appropriate approach to creating or utilizing plug-ins Each approach will be used once.
Note: To change your responses, you may deselect your response by clicking the blank space at the top of the selection list.

The Answer Is:
Explanation:
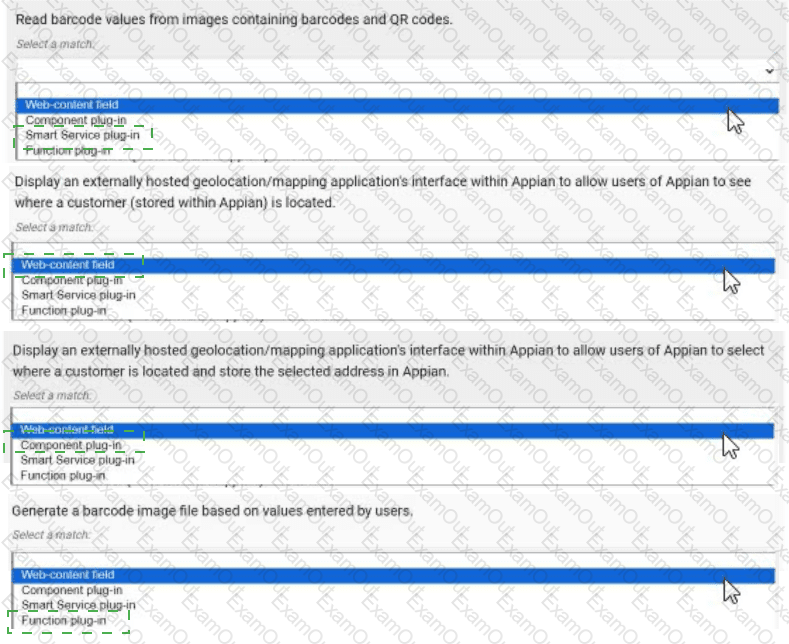
Read barcode values from images containing barcodes and QR codes. → Smart Service plug-in
Display an externally hosted geolocation/mapping application’s interface within Appian to allow users of Appian to see where a customer (stored within Appian) is located. → Web-content field
Display an externally hosted geolocation/mapping application’s interface within Appian to allow users of Appian to select where a customer is located and store the selected address in Appian. → Component plug-in
Generate a barcode image file based on values entered by users. → Function plug-in
Comprehensive and Detailed In-Depth Explanation:
Appian plug-ins extend functionality by integrating custom Java code into the platform. The four approaches—Web-content field, Component plug-in, Smart Service plug-in, and Function plug-in—serve distinct purposes, and each requirement must be matched to the most appropriate one based on its use case. Appian’s Plug-in Development Guide provides the framework for these decisions.
Read barcode values from images containing barcodes and QR codes → Smart Service plug-in:This requirement involves processing image data to extract barcode or QR code values, a task that typically occurs within a process model (e.g., as part of a workflow). A Smart Service plug-in is ideal because it allows custom Java logic to be executed as a node in a process, enabling the decoding of images and returning the extracted values to Appian. This approach integrates seamlessly with Appian’s process automation, making it the best fit for data extraction tasks.
Display an externally hosted geolocation/mapping application’s interface within Appian to allow users of Appian to see where a customer (stored within Appian) is located → Web-content field:This requires embedding an external mapping interface (e.g., Google Maps) within an Appian interface. A Web-content field is the appropriate choice, as it allows you to embed HTML, JavaScript, or iframe content from an external source directly into an Appian form or report. This approach is lightweight and does not require custom Java development, aligning with Appian’s recommendation for displaying external content without interactive data storage.
Display an externally hosted geolocation/mapping application’s interface within Appian to allow users of Appian to select where a customer is located and store the selected address in Appian → Component plug-in:This extends the previous requirement by adding interactivity (selecting an address) and data storage. A Component plug-in is suitable because it enables the creation of a custom interface component (e.g., a map selector) that can be embedded in Appian interfaces. The plug-in can handle user interactions, communicate with the external mapping service, and update Appian data stores, offering a robust solution for interactive external integrations.
Generate a barcode image file based on values entered by users → Function plug-in:This involves generating an image file dynamically based on user input, a task that can be executed within an expression or interface. A Function plug-in is the best match, as it allows custom Java logic to be called as an expression function (e.g., pluginGenerateBarcode(value)), returning the generated image. This approach is efficient for single-purpose operations and integrates well with Appian’s expression-based design.
Matching Rationale:
Each approach is used once, as specified, covering the spectrum of plug-in types: Smart Service for process-level tasks, Web-content field for static external display, Component plug-in for interactive components, and Function plug-in for expression-level operations.
Appian’s plug-in framework discourages overlap (e.g., using a Smart Service for display or a Component for process tasks), ensuring the selected matches align with intended use cases.
You are reviewing the Engine Performance Logs in Production for a single application that has been live for six months. This application experiences concurrent user activity and has a fairly sustained load during business hours. The client has reported performance issues with the application during business hours.
During your investigation, you notice a high Work Queue - Java Work Queue Size value in the logs. You also notice unattended process activities, including timer events and sending notification emails, are taking far longer to execute than normal.
The client increased the number of CPU cores prior to the application going live.
What is the next recommendation?
Add more engine replicas.
Optimize slow-performing user interfaces.
Add more application servers.
Add execution and analytics shards
The Answer Is:
AExplanation:
As an Appian Lead Developer, analyzing Engine Performance Logs to address performance issues in a Production application requires understanding Appian’s architecture and the specific metrics described. The scenario indicates a high “Work Queue - Java Work Queue Size,” which reflects a backlog of tasks in the Java Work Queue (managed by Appian engines), and delays in unattended process activities (e.g., timer events, email notifications). These symptoms suggest the Appian engines are overloaded, despite the client increasing CPU cores. Let’s evaluate each option:
A. Add more engine replicas:This is the correct recommendation. In Appian, engine replicas (part of the Appian Engine cluster) handle process execution, including unattended tasks like timers and notifications. A high Java Work Queue Size indicates the engines are overwhelmed by concurrent activity during business hours, causing delays. Adding more engine replicas distributes the workload, reducing queue size and improving performance for both user-driven and unattended tasks. Appian’s documentation recommends scaling engine replicas to handle sustained loads, especially in Production with high concurrency. Since CPU cores were already increased (likely on application servers), the bottleneck is likely the engine capacity, not the servers.
B. Optimize slow-performing user interfaces:While optimizing user interfaces (e.g., SAIL forms, reports) can improve user experience, the scenario highlights delays in unattended activities (timers, emails), not UI performance. The Java Work Queue Size issue points to engine-level processing, not UI rendering, so this doesn’t address the root cause. Appian’s performance tuning guidelines prioritize engine scaling for queue-related issues, making this a secondary concern.
C. Add more application servers:Application servers handle web traffic (e.g., SAIL interfaces, API calls), not process execution or unattended tasks managed by engines. Increasing application servers would help with UI concurrency but wouldn’t reduce the Java Work Queue Size or speed up timer/email processing, as these are engine responsibilities. Since the client already increased CPU cores (likely on application servers), this is redundant and unrelated to the issue.
D. Add execution and analytics shards:Execution shards (for process data) and analytics shards (for reporting) are part of Appian’s data fabric for scalability, but they don’t directly address engine workload or Java Work Queue Size. Shards optimize data storage and query performance, not real-time process execution. The logs indicate an engine bottleneck, not a data storage issue, so this isn’t relevant. Appian’s documentation confirms shards are for long-term scaling, not immediate performance fixes.
Conclusion: Adding more engine replicas (A) is the next recommendation. It directly resolves the high Java Work Queue Size and delays in unattended tasks, aligning with Appian’s architecture for handling concurrent loads in Production. This requires collaboration with system administrators to configure additional replicas in the Appian cluster.
You are the project lead for an Appian project with a supportive product owner and complex business requirements involving a customer management system. Each week, you notice the product owner becoming more irritated and not devoting as much time to the project, resulting in tickets becoming delayed due to a lack of involvement. Which two types of meetings should you schedule to address this issue?
An additional daily stand-up meeting to ensure you have more of the product owner’s time.
A risk management meeting with your program manager to escalate the delayed tickets.
A sprint retrospective with the product owner and development team to discuss team performance.
A meeting with the sponsor to discuss the product owner’s performance and request a replacement.
The Answer Is:
B, CExplanation:
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, managing stakeholder engagement and ensuring smooth project progress are critical responsibilities. The scenario describes a product owner whose decreasing involvement is causing delays, which requires a proactive and collaborative approach rather than an immediate escalation to replacement. Let’s analyze each option:
A. An additional daily stand-up meeting: While daily stand-ups are a core Agile practice to align the team, adding another one specifically to secure the product owner’s time is inefficient. Appian’s Agile methodology (aligned with Scrum) emphasizes that stand-ups are for the development team to coordinate, not to force stakeholder availability. The product owner’s irritation might increase with additional meetings, making this less effective.
B. A risk management meeting with your program manager: This is a correct choice. Appian Lead Developer documentation highlights the importance of risk management in complex projects (e.g., customer management systems). Delays due to lack of product owner involvement constitute a project risk. Escalating this to the program manager ensures visibility and allows for strategic mitigation, such as resource reallocation or additional support, without directly confronting the product owner in a way that could damage the relationship. This aligns with Appian’s project governance best practices.
C. A sprint retrospective with the product owner and development team: This is also a correct choice. The sprint retrospective, as per Appian’s Agile guidelines, is a key ceremony to reflect on what’s working and what isn’t. Including the product owner fosters collaboration and provides a safe space to address their reduced involvement and its impact on ticket delays. It encourages team accountability and aligns with Appian’s focus on continuous improvement in Agile development.
D. A meeting with the sponsor to discuss the product owner’s performance and request a replacement: This is premature and not recommended as a first step. Appian’s Lead Developer training emphasizes maintaining strong stakeholder relationships and resolving issues collaboratively before escalating to drastic measures like replacement. This option risks alienating the product owner and disrupting the project further, which contradicts Appian’s stakeholder management principles.
Conclusion: The best approach combines B (risk management meeting) to address the immediate risk of delays with a higher-level escalation and C (sprint retrospective) to collaboratively resolve the product owner’s engagement issues. These align with Appian’s Agile and leadership strategies for Lead Developers.
On the latest Health Check report from your Cloud TEST environment utilizing a MongoDB add-on, you note the following findings:
Category: User Experience, Description: # of slow query rules, Risk: High
Category: User Experience, Description: # of slow write to data store nodes, Risk: High
Which three things might you do to address this, without consulting the business?
Reduce the batch size for database queues to 10.
Optimize the database execution using standard database performance troubleshooting methods and tools (such as query execution plans).
Reduce the size and complexity of the inputs. If you are passing in a list, consider whether the data model can be redesigned to pass single values instead.
Optimize the database execution. Replace the view with a materialized view.
Use smaller CDTs or limit the fields selected in a!queryEntity().
The Answer Is:
B, C, EExplanation:
Comprehensive and Detailed In-Depth Explanation:
The Health Check report indicates high-risk issues with slow query rules and slow writes to data store nodes in a MongoDB-integrated Appian Cloud TEST environment. As a Lead Developer, you can address these performance bottlenecks without business consultation by focusing on technical optimizations within Appian and MongoDB. The goal is to improve user experience by reducing query and write latency.
Option B (Optimize the database execution using standard database performance troubleshooting methods and tools (such as query execution plans)):This is a critical step. Slow queries and writes suggest inefficient database operations. Using MongoDB’s explain() or equivalent tools to analyze execution plans can identify missing indices, suboptimal queries, or full collection scans. Appian’s Performance Tuning Guide recommends optimizing database interactions by adding indices on frequently queried fields or rewriting queries (e.g., using projections to limit returned data). This directly addresses both slow queries and writes without business input.
Option C (Reduce the size and complexity of the inputs. If you are passing in a list, consider whether the data model can be redesigned to pass single values instead):Large or complex inputs (e.g., large arrays in a!queryEntity() or write operations) can overwhelm MongoDB, especially in Appian’s data store integration. Redesigning the data model to handle single values or smaller batches reduces processing overhead. Appian’s Best Practices for Data Store Design suggest normalizing data or breaking down lists into manageable units, which can mitigate slow writes and improve query performance without requiring business approval.
Option E (Use smaller CDTs or limit the fields selected in a!queryEntity()): Appian Custom Data Types (CDTs) and a!queryEntity() calls that return excessive fields can increase data transfer and processing time, contributing to slow queries. Limiting fields to only those needed (e.g., using fetchTotalCount selectively) or using smaller CDTs reduces the load on MongoDB and Appian’s engine. This optimization is a technical adjustment within the developer’s control, aligning with Appian’s Query Optimization Guidelines.
Option A (Reduce the batch size for database queues to 10):While adjusting batch sizes can help with write performance, reducing it to 10 without analysis might not address the root cause and could slow down legitimate operations. This requires testing and potentially business input on acceptable performance trade-offs, making it less immediate.
Option D (Optimize the database execution. Replace the view with a materialized view):Materialized views are not natively supported in MongoDB (unlike relational databases like PostgreSQL), and Appian’s MongoDB add-on relies on collection-based storage. Implementing this would require significant redesign or custom aggregation pipelines, which may exceed the scope of a unilateral technical fix and could impact business logic.
These three actions (B, C, E) leverage Appian and MongoDB optimization techniques, addressing both query and write performance without altering business requirements or processes.
You are asked to design a case management system for a client. In addition to storing some basic metadata about a case, one of the client’s requirements is the ability for users to update a case. The client would like any user in their organization of 500 people to be able to make these updates. The users are all based in the company's headquarters, and there will be frequent cases where users are attempting to edit the same case. The client wants to ensure no information is lost when these edits occur and does not want the solution to burden their process administrators with any additional effort. Which data locking approach should you recommend?
Allow edits without locking the case CDI.
Use the database to implement low-level pessimistic locking.
Add an @Version annotation to the case CDT to manage the locking.
Design a process report and query to determine who opened the edit form first.
The Answer Is:
CExplanation:
Comprehensive and Detailed In-Depth Explanation:
The requirement involves a case management system where 500 users may simultaneously edit the same case, with a need to prevent data loss and minimize administrative overhead. Appian’s data management and concurrency control strategies are critical here, especially when integrating with an underlying database.
Option C (Add an @Version annotation to the case CDT to manage the locking):This is the recommended approach. In Appian, the @Version annotation on a Custom Data Type (CDT) enables optimistic locking, a lightweight concurrency control mechanism. When a user updates a case, Appian checks the version number of the CDT instance. If another user has modified it in the meantime, the update fails, prompting the user to refresh and reapply changes. This prevents data loss without requiring manual intervention by process administrators. Appian’s Data Design Guide recommends @Version for scenarios with high concurrency (e.g., 500 users) and frequent edits, as it leverages the database’s native versioning (e.g., in MySQL or PostgreSQL) and integrates seamlessly with Appian’s process models. This aligns with the client’s no-burden requirement.
Option A (Allow edits without locking the case CDI):This is risky. Without locking, simultaneous edits could overwrite each other, leading to data loss—a direct violation of the client’s requirement. Appian does not recommend this for collaborative environments.
Option B (Use the database to implement low-level pessimistic locking):Pessimistic locking (e.g., using SELECT ... FOR UPDATE in MySQL) locks the record during the edit process, preventing other users from modifying it until the lock is released. While effective, it can lead to deadlocks or performance bottlenecks with 500 users, especially if edits are frequent. Additionally, managing this at the database level requires custom SQL and increases administrative effort (e.g., monitoring locks), which the client wants to avoid. Appian prefers higher-level solutions like @Version over low-level database locking.
Option D (Design a process report and query to determine who opened the edit form first):This is impractical and inefficient. Building a custom report and query to track form opens adds complexity and administrative overhead. It doesn’t inherently prevent data loss and relies on manual resolution, conflicting with the client’s requirements.
The @Version annotation provides a robust, Appian-native solution that balances concurrency, data integrity, and ease of maintenance, making it the best fit.
You are reviewing log files that can be accessed in Appian to monitor and troubleshoot platform-based issues.
For each type of log file, match the corresponding Information that it provides. Each description will either be used once, or not at all.
Note: To change your responses, you may deselect your response by clicking the blank space at the top of the selection list.

The Answer Is:
Explanation:
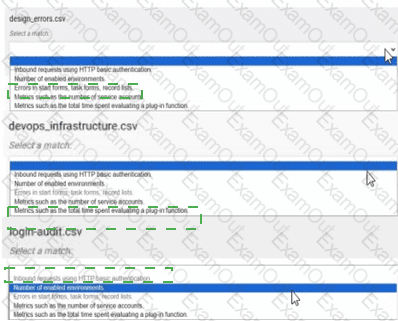
design_errors.csv → Errors in start forms, task forms, record lists, enabled environments
devops_infrastructure.csv → Metrics such as the total time spent evaluating a plug-in function
login-audit.csv → Inbound requests using HTTP basic authentication
Comprehensive and Detailed In-Depth Explanation:
Appian provides various log files to monitor and troubleshoot platform issues, accessible through the Administration Console or exported as CSV files. These logs capture different aspects of system performance, security, and user interactions. The Appian Monitoring and Troubleshooting Guide details the purpose of each log file, enabling accurate matching.
design_errors.csv → Errors in start forms, task forms, record lists, enabled environments:The design_errors.csv log file is specifically designed to track errors related to the design and runtime behavior of Appian objects such as start forms, task forms, and record lists. It also includes information about issues in enabled environments, making it the appropriate match. This log helps developers identify and resolve UI or configuration errors, aligning with its purpose of capturing design-time and runtime issues.
devops_infrastructure.csv → Metrics such as the total time spent evaluating a plug-in function:The devops_infrastructure.csv log file provides infrastructure and performance metrics for Appian Cloud instances. It includes data on system performance, such as the time spent evaluating plug-in functions, which is critical for optimizing custom integrations. This matches the description, as it focuses on operational metrics rather than errors or security events, consistent with Appian’s infrastructure monitoring approach.
login-audit.csv → Inbound requests using HTTP basic authentication:The login-audit.csv log file tracks user authentication and login activities, including details about inbound requests using HTTP basic authentication. This log is used to monitor security events, such as successful and failed login attempts, making it the best fit for this description. Appian’s security logging emphasizes audit trails for authentication, aligning with this use case.
Unused Description:
Number of enabled environments: This description is not matched to any log file. While it could theoretically relate to system configuration logs, none of the listed files (design_errors.csv, devops_infrastructure.csv, login-audit.csv) are specifically designed to report the number of enabled environments. This might be tracked in a separate administrative report or configuration log not listed here.
Matching Rationale:
Each description is either used once or not at all, as specified. The matches are based on Appian’s documented log file purposes: design_errors.csv for design-related errors, devops_infrastructure.csv for performance metrics, and login-audit.csv for authentication details.
The unused description suggests the question allows for some descriptions to remain unmatched, reflecting real-world variability in log file content.
