A company has built more than 50 models and deployed the models on Amazon SageMaker Al as real-time inference
endpoints. The company needs to reduce the costs of the SageMaker Al inference endpoints. The company used the same
ML framework to build the models. The company ' s customers require low-latency access to the models.
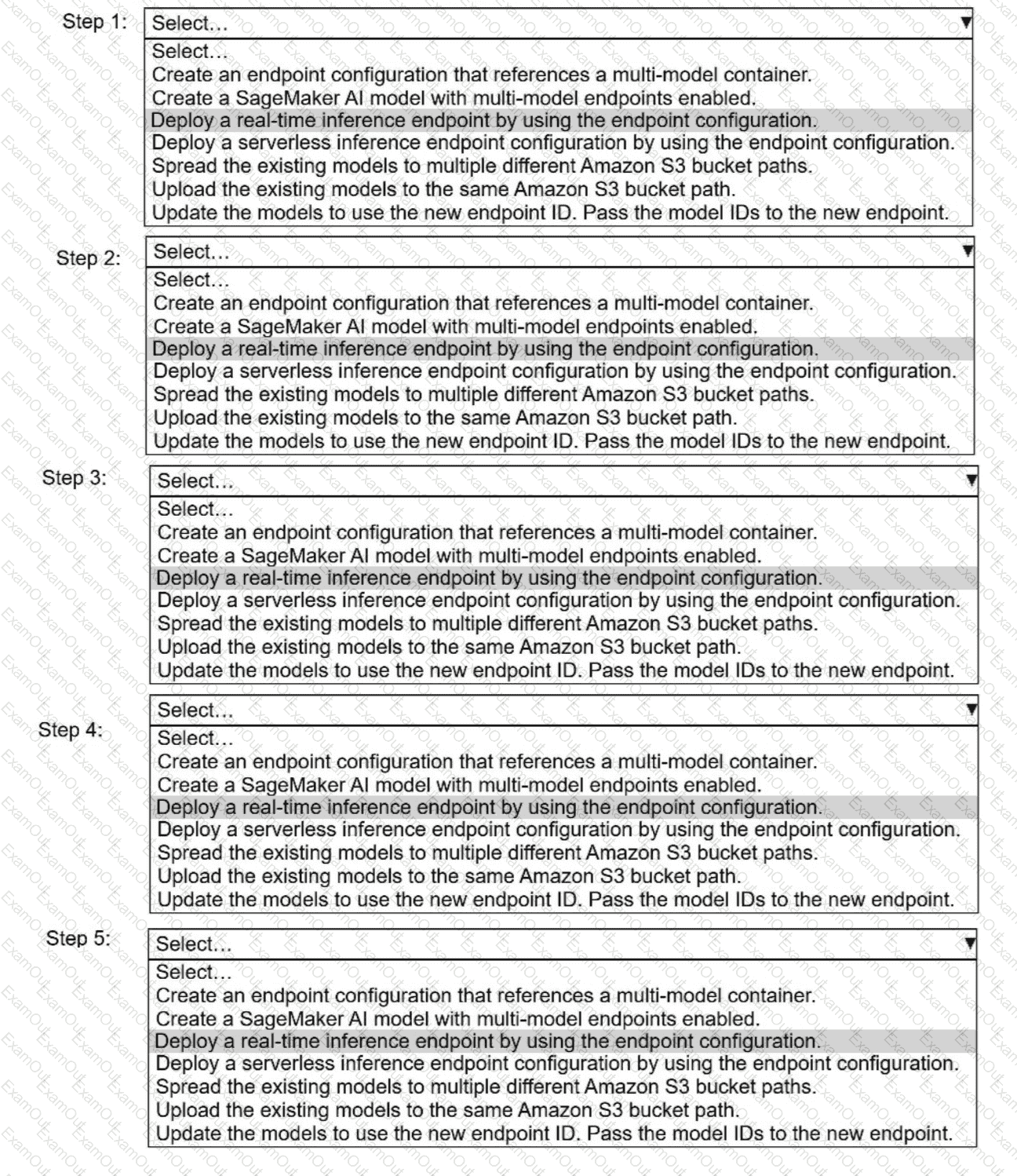
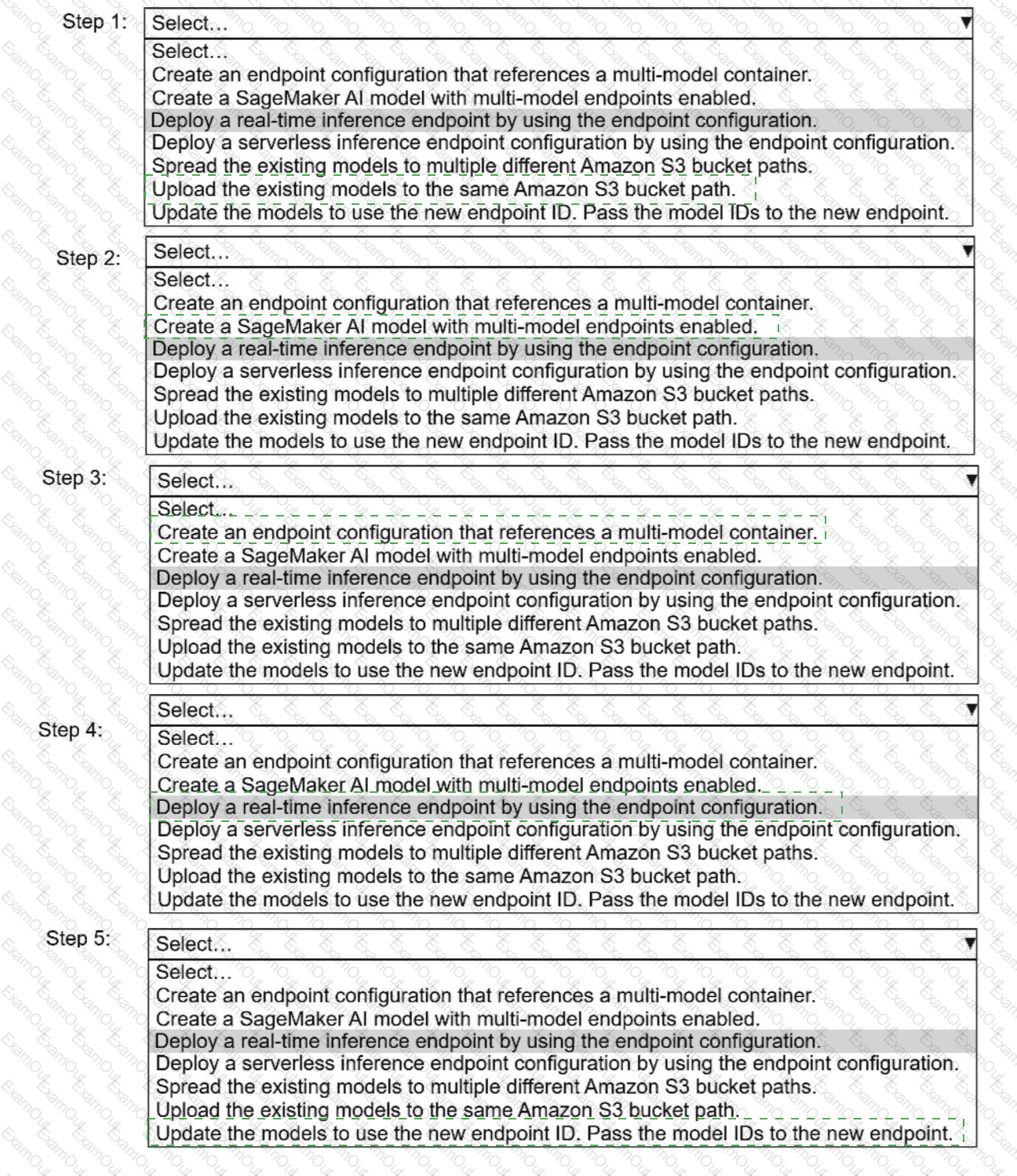
Select and order the correct steps from the following list to reduce the cost of inference and keep latency low. Select each
step one time or not at all. (Select and order FIVE.)
· Create an endpoint configuration that references a multi-model container.
. Create a SageMaker Al model with multi-model endpoints enabled.
. Deploy a real-time inference endpoint by using the endpoint configuration.
. Deploy a serverless inference endpoint configuration by using the endpoint configuration.
· Spread the existing models to multiple different Amazon S3 bucket paths.
. Upload the existing models to the same Amazon S3 bucket path.
. Update the models to use the new endpoint ID. Pass the model IDs to the new endpoint.
A financial company receives a high volume of real-time market data streams from an external provider. The streams consist of thousands of JSON records per second.
The company needs a scalable AWS solution to identify anomalous data points with the LEAST operational overhead.
Which solution will meet these requirements?
A company is using ML to predict the presence of a specific weed in a farmer ' s field. The company is using the Amazon SageMaker linear learner built-in algorithm with a value of multiclass_dassifier for the predictorjype hyperparameter.
What should the company do to MINIMIZE false positives?
A company needs to run a batch data-processing job on Amazon EC2 instances. The job will run during the weekend and will take 90 minutes to finish running. The processing can handle interruptions. The company will run the job every weekend for the next 6 months.
Which EC2 instance purchasing option will meet these requirements MOST cost-effectively?
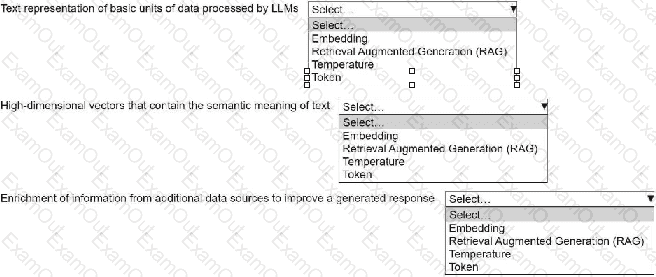
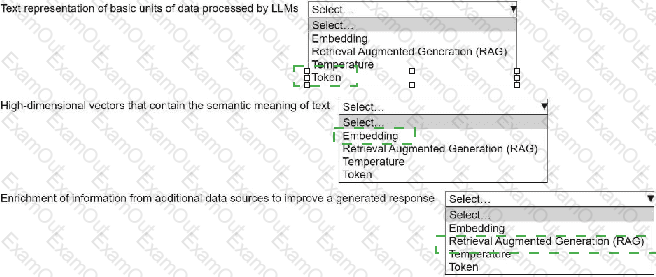
An ML engineer is building a generative AI application on Amazon Bedrock by using large language models (LLMs).
Select the correct generative AI term from the following list for each description. Each term should be selected one time or not at all. (Select three.)
• Embedding
• Retrieval Augmented Generation (RAG)
• Temperature
• Token

A company stores time-series data about user clicks in an Amazon S3 bucket. The raw data consists of millions of rows of user activity every day. ML engineers access the data to develop their ML models.
The ML engineers need to generate daily reports and analyze click trends over the past 3 days by using Amazon Athena. The company must retain the data for 30 days before archiving the data.
Which solution will provide the HIGHEST performance for data retrieval?
A company needs to ingest data from data sources into Amazon SageMaker Data Wrangler. The data sources are Amazon S3, Amazon Redshift, and Snowflake. The ingested data must always be up to date with the latest changes in the source systems.
Which solution will meet these requirements?
A company regularly receives new training data from a vendor of an ML model. The vendor delivers cleaned and prepared data to the company’s Amazon S3 bucket every 3–4 days.
The company has an Amazon SageMaker AI pipeline to retrain the model. An ML engineer needs to run the pipeline automatically when new data is uploaded to the S3 bucket.
Which solution will meet these requirements with the LEAST operational effort?
A company has a Retrieval Augmented Generation (RAG) application that uses a vector database to store embeddings of documents. The company must migrate the application to AWS and must implement a solution that provides semantic search of text files. The company has already migrated the text repository to an Amazon S3 bucket.
Which solution will meet these requirements?
An ML engineer is building a model to predict house and apartment prices. The model uses three features: Square Meters, Price, and Age of Building. The dataset has 10,000 data rows. The data includes data points for one large mansion and one extremely small apartment.
The ML engineer must perform preprocessing on the dataset to ensure that the model produces accurate predictions for the typical house or apartment.
Which solution will meet these requirements?
