A company is developing an internal cost-estimation tool that uses an ML model in Amazon SageMaker AI. Users upload high-resolution images to the tool.
The model must process each image and predict the cost of the object in the image. The model also must notify the user when processing is complete.
Which solution will meet these requirements?
Case study
An ML engineer is developing a fraud detection model on AWS. The training dataset includes transaction logs, customer profiles, and tables from an on-premises MySQL database. The transaction logs and customer profiles are stored in Amazon S3.
The dataset has a class imbalance that affects the learning of the model ' s algorithm. Additionally, many of the features have interdependencies. The algorithm is not capturing all the desired underlying patterns in the data.
After the data is aggregated, the ML engineer must implement a solution to automatically detect anomalies in the data and to visualize the result.
Which solution will meet these requirements?
A company wants to build an anomaly detection ML model. The model will use large-scale tabular data that is stored in an Amazon S3 bucket. The company does not have expertise in Python, Spark, or other languages for ML.
An ML engineer needs to transform and prepare the data for ML model training.
Which solution will meet these requirements?
A company wants to migrate ML models from an on-premises environment to Amazon SageMaker AI. The models are based on the PyTorch algorithm. The company needs to reuse its existing custom scripts as much as possible.
Which SageMaker AI feature should the company use?
A company is using Amazon SageMaker and millions of files to train an ML model. Each file is several megabytes in size. The files are stored in an Amazon S3 bucket. The company needs to improve training performance.
Which solution will meet these requirements in the LEAST amount of time?
A company runs an Amazon SageMaker domain in a public subnet of a newly created VPC. The network is configured properly, and ML engineers can access the SageMaker domain.
Recently, the company discovered suspicious traffic to the domain from a specific IP address. The company needs to block traffic from the specific IP address.
Which update to the network configuration will meet this requirement?
A company wants to develop an ML model by using tabular data from its customers. The data contains meaningful ordered features with sensitive information that should not be discarded. An ML engineer must ensure that the sensitive data is masked before another team starts to build the model.
Which solution will meet these requirements?
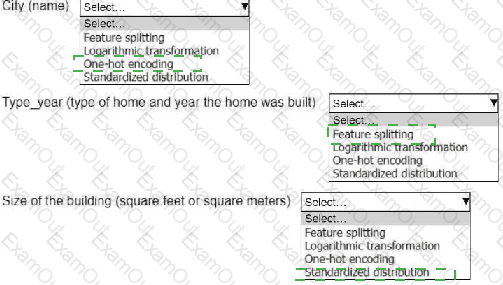
An ML engineer is working on an ML model to predict the prices of similarly sized homes. The model will base predictions on several features The ML engineer will use the following feature engineering techniques to estimate the prices of the homes:
• Feature splitting
• Logarithmic transformation
• One-hot encoding
• Standardized distribution
Select the correct feature engineering techniques for the following list of features. Each feature engineering technique should be selected one time or not at all (Select three.)

A company uses an Amazon EMR cluster to run a data ingestion process for an ML model. An ML engineer notices that the processing time is increasing.
Which solution will reduce the processing time MOST cost-effectively?
An ML engineer is analyzing a classification dataset before training a model in Amazon SageMaker AI. The ML engineer suspects that the dataset has a significant imbalance between class labels that could lead to biased model predictions. To confirm class imbalance, the ML engineer needs to select an appropriate pre-training bias metric.
Which metric will meet this requirement?
