The following DDL command was used to create a task based on a stream:

Assuming MY_WH is set to auto_suspend – 60 and used exclusively for this task, which statement is true?
An Architect for a multi-national transportation company has a system that is used to check the weather conditions along vehicle routes. The data is provided to drivers.
The weather information is delivered regularly by a third-party company and this information is generated as JSON structure. Then the data is loaded into Snowflake in a column with a VARIANT data type. This
table is directly queried to deliver the statistics to the drivers with minimum time lapse.
A single entry includes (but is not limited to):
- Weather condition; cloudy, sunny, rainy, etc.
- Degree
- Longitude and latitude
- Timeframe
- Location address
- Wind
The table holds more than 10 years' worth of data in order to deliver the statistics from different years and locations. The amount of data on the table increases every day.
The drivers report that they are not receiving the weather statistics for their locations in time.
What can the Architect do to deliver the statistics to the drivers faster?
Why might a Snowflake Architect use a star schema model rather than a 3NF model when designing a data architecture to run in Snowflake? (Select TWO).
How do Snowflake databases that are created from shares differ from standard databases that are not created from shares? (Choose three.)
A user has the appropriate privilege to see unmasked data in a column.
If the user loads this column data into another column that does not have a masking policy, what will occur?
A company is trying to Ingest 10 TB of CSV data into a Snowflake table using Snowpipe as part of Its migration from a legacy database platform. The records need to be ingested in the MOST performant and cost-effective way.
How can these requirements be met?
An Architect has been asked to clone schema STAGING as it looked one week ago, Tuesday June 1st at 8:00 AM, to recover some objects.
The STAGING schema has 50 days of retention.
The Architect runs the following statement:
CREATE SCHEMA STAGING_CLONE CLONE STAGING at (timestamp => '2021-06-01 08:00:00');
The Architect receives the following error: Time travel data is not available for schema STAGING. The requested time is either beyond the allowed time travel period or before the object creation time.
The Architect then checks the schema history and sees the following:
CREATED_ON|NAME|DROPPED_ON
2021-06-02 23:00:00 | STAGING | NULL
2021-05-01 10:00:00 | STAGING | 2021-06-02 23:00:00
How can cloning the STAGING schema be achieved?
A DevOps team has a requirement for recovery of staging tables used in a complex set of data pipelines. The staging tables are all located in the same staging schema. One of the requirements is to have online recovery of data on a rolling 7-day basis.
After setting up the DATA_RETENTION_TIME_IN_DAYS at the database level, certain tables remain unrecoverable past 1 day.
What would cause this to occur? (Choose two.)
When activating Tri-Secret Secure in a hierarchical encryption model in a Snowflake account, at what level is the customer-managed key used?
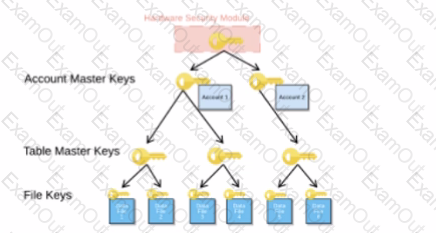
A Snowflake Architect is setting up database replication to support a disaster recovery plan. The primary database has external tables.
How should the database be replicated?
