You create an Azure Machine Learning workspace.
You must use the Python SDK v2 to implement an experiment from a Jupyter notebook in the workspace. The experiment must log string metrics. You need to implement the method to log the string metrics. Which method should you use?
You manage an Azure Machine Learning workspace. The Pylhon scrip! named scriptpy reads an argument named training_data. The trainlng.data argument specifies the path to the training data in a file named datasetl.csv.
You plan to run the scriptpy Python script as a command job that trains a machine learning model.
You need to provide the command to pass the path for the datasct as a parameter value when you submit the script as a training job.
Solution: python script.py –training_data dataset1,csv
Does the solution meet the goal?
You manage an Azure Machine Learning workspace named workspace1 and a Data Science Virtual Machine (DSVM) named DSMV1.
You must an experiment in DSMV1 by using a Jupiter notebook and Python SDK v2 code. You must store metrics and artifacts in workspace 1 You start by creating Python SCK v2 code to import ail required packages.
You need to implement the Python SOK v2 code to store metrics and article in workspace1.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them the correctly order.


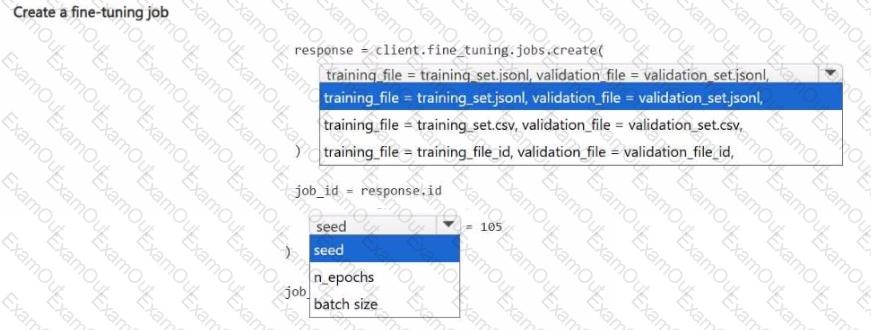
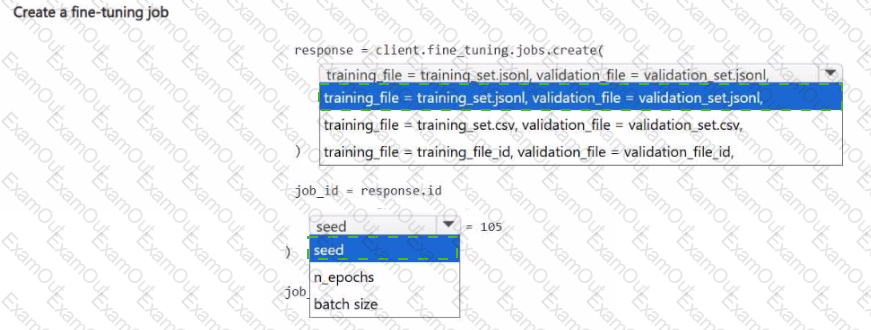
You manage an Azure Al Foundry project.
You plan to fine-tune a base model by using pre-uploaded training and validation data. You must specify a hyperparameter to ensure the job is reproducible.
You need to submit the fine-tuning training job.
How should you complete the Python code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You manage an Azure Machine Learning workspace. You use Azure Machine Learning Python SDK v2 to configure a trigger to schedule a pipeline job. You need to create a time-based schedule with recurrence pattern.
Which two properties must you use to successfully configure the trigger? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
You create and register a model in an Azure Machine Learning workspace.
You must use the Azure Machine Learning SDK to implement a batch inference pipeline that uses a ParallelRunStep to score input data using the model. You must specify a value for the ParallelRunConfig compute_target setting of the pipeline step.
You need to create the compute target.
Which class should you use?
You have an Azure Machine Learning workspace. You are running an experiment on your local computer.
You need to ensure that you can use MLflow Tracking with Azure Machine Learning Python SDK v2 to store metrics and artifacts from your local experiment runs in the workspace.
In which order should you perform the actions? To answer, move all actions from the list of actions to the answer area and arrange them in the correct order.


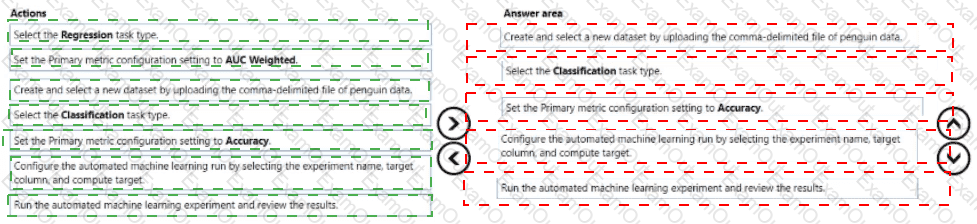
You are creating a machine learning model that can predict the species of a penguin from its measurements. You have a file that contains measurements for free species of penguin in comma delimited format.
The model must be optimized for area under the received operating characteristic curve performance metric averaged for each class.
You need to use the Automated Machine Learning user interface in Azure Machine Learning studio to run an experiment and find the best performing model.
Which five actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the collect order.

Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are using Azure Machine Learning to run an experiment that trains a classification model.
You want to use Hyperdrive to find parameters that optimize the AUC metric for the model. You configure a HyperDriveConfig for the experiment by running the following code:

You plan to use this configuration to run a script that trains a random forest model and then tests it with validation data. The label values for the validation data are stored in a variable named y_test variable, and the predicted probabilities from the model are stored in a variable named y_predicted.
You need to add logging to the script to allow Hyperdrive to optimize hyperparameters for the AUC metric. Solution: Run the following code:
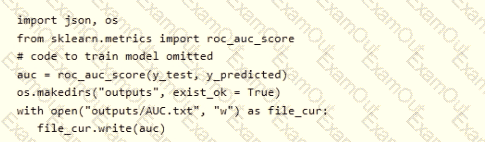
Does the solution meet the goal?
You plan to use the Hyperdrive feature of Azure Machine Learning to determine the optimal hyperparameter values when training a model.
You must use Hyperdrive to try combinations of the following hyperparameter values:
• learning_rate: any value between 0.001 and 0.1
• batch_size: 16, 32, or 64
You need to configure the search space for the Hyperdrive experiment.
Which two parameter expressions should you use? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
