RMSE is a good measure of accuracy, but only to compare forecasting errors of different models for a______, as it is scale-dependent.
Regularization is a very important technique in machine learning to prevent overfitting. Mathematically speaking, it adds a regularization term in order to prevent the coefficients to fit so perfectly to overfit. The difference between the L1 and L2 is...
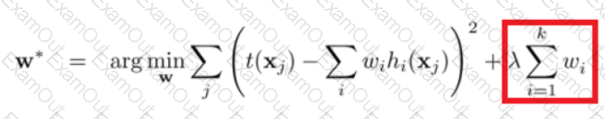 A picture containing text
Description automatically generated
A picture containing text
Description automatically generatedDigit recognition, is an example of.....
What type of output generated in case of linear regression?
Which of the following are advantages of the Support Vector machines?
Select the correct option from the below
Your company has organized an online campaign for feedback on product quality and you have all the responses for the product reviews, in the response form people have check box as well as text field. Now you know that people who do not fill in or write non-dictionary word in the text field are not considered valid feedback. People who fill in text field with proper English words are considered valid response. Which of the following method you should not use to identify whether the response is valid or not?
Select the correct statement which applies to K-Nearest Neighbors
Which of the following statement is true for the R square value in the regression model?
What describes a true limitation of Logistic Regression method?
