A data engineer needs to create a table in Databricks using data from their organization’s existing SQLite database.
They run the following command:
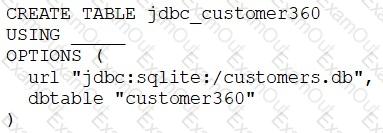
Which of the following lines of code fills in the above blank to successfully complete the task?
A data engineer wants to create a data entity from a couple of tables. The data entity must be used by other data engineers in other sessions. It also must be saved to a physical location.
Which of the following data entities should the data engineer create?
A data engineer has a Job that has a complex run schedule, and they want to transfer that schedule to other Jobs.
Rather than manually selecting each value in the scheduling form in Databricks, which of the following tools can the data engineer use to represent and submit the schedule programmatically?
A data engineer is building a nightly batch ETL pipeline that processes very large volumes of raw JSON logs from a data lake into Delta tables for reporting. The data arrives in bulk once per day, and the pipeline takes several hours to complete. Cost efficiency is important , but performance and reliable completion of the pipeline are the highest priorities.
Which type of Databricks cluster should the data engineer configure?
A data engineer wants to create a new table containing the names of customers who live in France.
They have written the following command:
CREATE TABLE customersInFrance
_____ AS
SELECT id,
firstName,
lastName
FROM customerLocations
WHERE country = ’FRANCE’;
A senior data engineer mentions that it is organization policy to include a table property indicating that the new table includes personally identifiable information (Pll).
Which line of code fills in the above blank to successfully complete the task?
A data engineer manages multiple external tables linked to various data sources. The data engineer wants to manage these external tables efficiently and ensure that only the necessary permissions are granted to users for accessing specific external tables.
How should the data engineer manage access to these external tables?
A data engineer needs to optimize the data layout and query performance for an e-commerce transactions Delta table. The table is partitioned by " purchase_date " a date column which helps with time-based queries but does not optimize searches on user statistics " customer_id " , a high-cardinality column.
The table is usually queried with filters on " customer_i
d " within specific date ranges, but since this data is spread across multiple files in each partition, it results in full partition scans and increased runtime and costs.
How should the data engineer optimize the Data Layout for efficient reads?
A data engineer has configured a Structured Streaming job to read from a table, manipulate the data, and then perform a streaming write into a new table.
The cade block used by the data engineer is below:

If the data engineer only wants the query to execute a micro-batch to process data every 5 seconds, which of the following lines of code should the data engineer use to fill in the blank?
A data engineering team is using Kafka to capture event data and then ingest it into Databricks. The team wants to be able to see these historical events. Medallion architecture is already in place. The team wants to be mindful of costs.
Where should this historical event data be stored?
A data engineer is writing a script that is meant to ingest new data from cloud storage. In the event of the Schema change, the ingestion should fail. It should fail until the changes downstream source can be found and verified as intended changes.
Which command will meet the requirements?
