A data scientist is developing a model to predict the outcome of a vote for a national mascot. The choice is between tigers and lions. The full data set represents feedback from individuals representing 17 professions and 12 different locations. The following rank aggregation represents 80% of the data set:
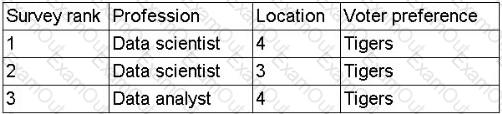
(Screenshot shows survey rankings for just two professions and a few locations, all voting for "Tigers")
Which of the following is the most likely concern about the model's ability to predict the outcome of the vote?
A data scientist is clustering a data set but does not want to specify the number of clusters present. Which of the following algorithms should the data scientist use?
Under perfect conditions, E. coli bacteria would cover the entire earth in a matter of days. Which of the following types of models is the best for explaining this type of growth?
A data scientist is building a model to predict customer credit scores based on information collected from reporting agencies. The model needs to automatically adjust its parameters to adapt to recent changes in the information collected. Which of the following is the best model to use?
A data scientist is preparing to brief a non-technical audience that is focused on analysis and results. During the modeling process, the data scientist produced the following artifacts:
Which of the following artifacts should the data scientist include in the briefing? (Choose two.)
