Which of the following metrics is being captured when performing principal component analysis?
Why do data skews happen in the ML pipeline?
Which two of the following criteria are essential for machine learning models to achieve before deployment? (Select two.)
In general, models that perform their tasks:
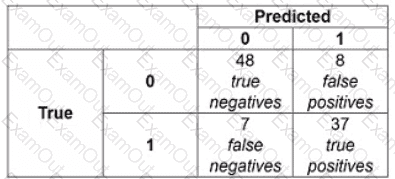
The following confusion matrix is produced when a classifier is used to predict labels on a test dataset. How precise is the classifier?
A healthcare company experiences a cyberattack, where the hackers were able to reverse-engineer a dataset to break confidentiality.
Which of the following is TRUE regarding the dataset parameters?
An organization sells house security cameras and has asked their data scientists to implement a model to detect human feces, as distinguished from animals, so they can alert th customers only when a human gets close to their house.
Which of the following algorithms is an appropriate option with a correct reason?
Which of the following approaches is best if a limited portion of your training data is labeled?
Which two of the following statements about the beta value in an A/B test are accurate? (Select two.)
Which of the following is TRUE about SVM models?
