An ML engineer wants to re-train an XGBoost model at the end of each month. A data team prepares the training data. The training dataset is a few hundred megabytes in size. When the data is ready, the data team stores the data as a new file in an Amazon S3 bucket.
The ML engineer needs a solution to automate this pipeline. The solution must register the new model version in Amazon SageMaker Model Registry within 24 hours.
Which solution will meet these requirements?
A company is running ML models on premises by using custom Python scripts and proprietary datasets. The company is using PyTorch. The model building requires unique domain knowledge. The company needs to move the models to AWS.
Which solution will meet these requirements with the LEAST effort?
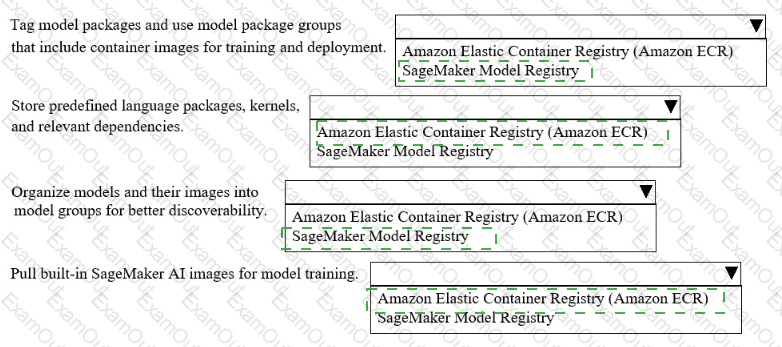
A company uses Amazon SageMakerAI to support ML workflows such as model training and deployment.
Select the correct registry from the following list to meet the requirements for each use case with the LEAST operational overhead. Each registry should be selected one or more times. (Select FOUR.)
• Amazon Elastic Container Registry (Amazon ECR)
• SageMaker Model Registry

An ML engineer normalized training data by using min-max normalization in AWS Glue DataBrew. The ML engineer must normalize the production inference data in the same way as the training data before passing the production inference data to the model for predictions.
Which solution will meet this requirement?
A logistics company has installed in-vehicle cameras for basic monitoring of its drivers. The company wants to improve driver safety by identifying distractions that could lead to accidents.
Which solution will meet this requirement with the LEAST operational effort?
A company ingests sales transaction data using Amazon Data Firehose into Amazon OpenSearch Service. The Firehose buffer interval is set to 60 seconds.
The company needs sub-second latency for a real-time OpenSearch dashboard.
Which architectural change will meet this requirement?
An ML engineer has an Amazon Comprehend custom model in Account A in the us-east-1 Region. The ML engineer needs to copy the model to Account В in the same Region.
Which solution will meet this requirement with the LEAST development effort?
An ML engineer is developing a neural network to run on new user data. The dataset has dozens of floating-point features. The dataset is stored as CSV objects in an Amazon S3 bucket. Most objects and columns are missing at least one value. All features are relatively uniform except for a small number of extreme outliers. The ML engineer wants to use Amazon SageMaker Data Wrangler to handle missing values before passing the dataset to the neural network.
Which solution will provide the MOST complete data?
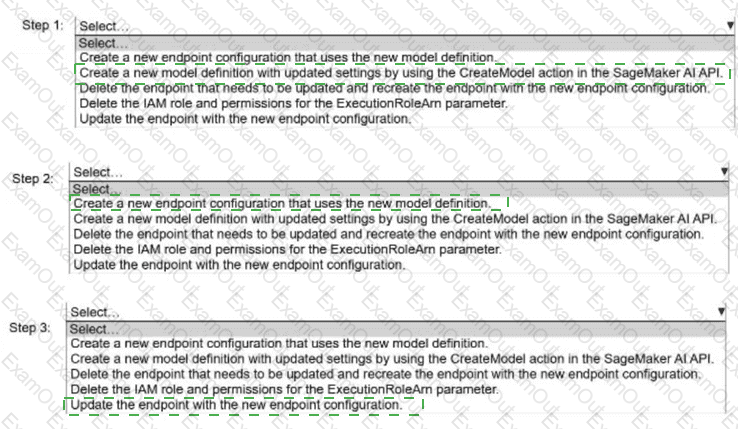
A company needs to update the model definition of an existing Amazon SageMaker Al endpoint.
Select and order the correct steps from the following list to update the model definition settings with the LEAST interruption of inferences. Select each step one time or not
at all. (Select and order THREE.)
Create a new endpoint configuration that uses the new model definition.
Create a new model definition with updated settings by using the CreateModel action in the SageMaker AI API.
Delete the endpoint that needs to be updated and recreate the endpoint with the new endpoint configuration.
Delete the IAM role and permissions for the ExecutionRoleArn parameter.
Update the endpoint with the new endpoint configuration.

A retail company is analyzing customer purchase data to develop personalized product recommendations. The company wants to use Amazon SageMaker Clarify to assess fairness metrics across different customer groups to avoid potential bias in the recommendation system.
The recommendation system needs to identify if certain customer segments are underrepresented in the training data. The company needs to choose a pre-training bias metric in SageMaker Clarify.
Which metric meets these requirements?
